2023. 12. 24. 22:28ㆍAI
구동 영상
후기 :
솔직히 ai가 쓴 댓글의 상태가 만족스럽진 않지만 편리하고,
앞으로 나올 ai모델은 더 나아지겠지라는 기대가 있습니다.
아래는 전체 코드와 코드별로 설명을 달아놓았습니다.
전체 코드
1. AI한테 질문하는 함수
from openai import OpenAI
client = OpenAI(api_key = "my api-key")
completion_MAX_TOKEN = 256
def generate_text(prompt, model="text-davinci-003", temperature=0, max_tokens=256, top_p=1, frequency_penalty=0, presence_penalty=0):
response = client.completions.create(
model=model,
prompt=prompt,
temperature=temperature,
max_tokens=max_tokens,
top_p=top_p,
frequency_penalty=frequency_penalty,
presence_penalty=presence_penalty
)
return response.choices[0].text
# 함수를 사용하는 예제
prompt_text = "반갑습니다."
generated_text = generate_text(prompt_text)
print(generated_text)
2. 토큰 세는 함수
!pip install tiktoken
import tiktoken
encoding = tiktoken.get_encoding("gpt2")
print(encoding)
print(type(encoding))
# cl100k_base gpt-4, gpt-3.5-turbo, text-embedding-ada-002
# p50k_base Codex models, text-davinci-002, text-davinci-003
# r50k_base (or gpt2) GPT-3 models like davinci
MAX_TOKEN = 4096
enc = tiktoken.encoding_for_model("text-davinci-003")
print(enc)
print(type(enc))
def tokens_from_string(string: str, encoding_name: str) -> list: #<class 'list'>
"""Returns the number of tokens in a text string."""
encoding = tiktoken.encoding_for_model(encoding_name)
encoded = encoding.encode(string)
return encoded
def string_from_tokens(tokens: list, decoding_name: str) -> str:
"""Returns the number of tokens in a text string."""
decoding = tiktoken.encoding_for_model(decoding_name)
decoded = decoding.decode(tokens)
return decoded
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.encoding_for_model(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
3. 실행 횟수 체크 함수
import os
def update_run_count(filename="run_count.txt"):
# 파일이 존재하지 않으면, 0으로 초기화
if not os.path.exists(filename):
with open(filename, "w") as file:
file.write("0")
# 파일에서 현재 실행 횟수 읽기
with open(filename, "r") as file:
count = int(file.read())
# 실행 횟수 업데이트 (1 증가)
count += 1
# 업데이트된 실행 횟수 저장
with open(filename, "w") as file:
file.write(str(count))
# 현재 실행 횟수 반환
return count
# 함수를 사용하여 실행 횟수를 출력
current_count = update_run_count()
print("이 프로그램은 지금까지", current_count, "번 실행되었습니다.")
4. 완료 시 알림창 띄우는 함수
import tkinter as tk
from tkinter import messagebox
def show_message(summary:str, context:str):
# Tkinter 윈도우 초기화
root = tk.Tk()
root.withdraw() # 메인 윈도우 숨기기
# 메인 윈도우를 최상위로 설정
root.attributes('-topmost', True)
# 메시지 박스 띄우기
messagebox.showinfo(summary,context)
# 메시지 박스가 닫힌 후 메인 윈도우 숨김 해제
root.destroy()
5. 메인 코드
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
import time
import sys#sys.exit()실행중지용
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
import tkinter as tk
from tkinter import messagebox
# 크롬 드라이버 설치 및 설정
service = Service(executable_path=ChromeDriverManager().install())
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
# 크롬 브라우저 열기
driver = webdriver.Chrome(service=service, options=options)
# 페이지의 로드 상태를 확인하는 자바스크립트
wait = WebDriverWait(driver, 10)
#화면 최대화해서 맨 앞으로 가져오기
driver.minimize_window()
driver.maximize_window()
# 원하는 사이트 접속
url = "https://weekreport.tistory.com/"
# driver.get(url)
driver.get("https://www.tistory.com/auth/login?redirectUrl=https%3A%2F%2Fweekreport.tistory.com#")
from selenium.webdriver.common.by import By
kakaologin=driver.find_element_by_xpath("/html/body/div[2]/div/div/div/div/div/a[2]")
kakaologin.click()
kakaologin_id=driver.find_element_by_xpath("/html/body/div/div/div/main/article/div/div/form/div[1]/div/input")
kakaologin_id.send_keys("abc@naver.com")
kakaologin_pw=driver.find_element_by_xpath("/html/body/div/div/div/main/article/div/div/form/div[2]/div/input")
kakaologin_pw.send_keys("myPasswd")#하드코딩 위험한 방식
kakaologin_btn=driver.find_element_by_xpath("/html/body/div/div/div/main/article/div/div/form/div[4]/button[1]")
kakaologin_btn.click()
# "link_num" 클래스를 가진 모든 요소 찾기
element = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'link_num')))
page_list = driver.find_elements(By.CLASS_NAME, 'link_num')
# 가장 마지막 요소의 href 속성 추출
last_href = page_list[-1].get_attribute('href')
# href에서 숫자(page 값) 추출
last_page_num = int(re.search(r'page=(\d+)', last_href).group(1))
# page=1부터 last_page_num까지의 URL 생성
page_urls = [f"{driver.current_url}?page={i}" for i in range(1, last_page_num+1)]
# 결과 출력 및 드라이버 종료
# URL을 저장할 리스트 초기화
givenrequest = "\n칭찬하는 말투로 댓글을 달꺼야. 기술에 대한 내용을 중점으로 30자 내외로 댓글을 출력해줘"
token_givenrequest = tokens_from_string(givenrequest,"text-davinci-003")
runCnt = update_run_count()
for page in page_urls :
article_urls = []
# 페이지의 로드 상태를 확인하는 자바스크립트
driver.get(page)
element = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'item_category')))
# 한 페이지에서 보이는 리스트
article_list = driver.find_elements(By.CLASS_NAME,'item_category')
# 각 항목의 url 담기
for article in article_list:
article_url = article.find_element(By.TAG_NAME, "a").get_attribute("href")
article_urls.append(article_url)
# 4번에서 만든 코드를 article_urls의 모든 요소에 반복 적용
for article_url in article_urls:
# 해당 URL로 이동
driver.get(article_url)
# # 4-3. 댓글 요소 찾기
element = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tt-cmt')))
reply_sel = driver.find_element(By.CLASS_NAME,'tt-cmt')
# # 본문 텍스트 추출
# /html/body/div[1]/div/main/div/div/div[2]/div[1]
main_text_element = driver.find_element_by_xpath('/html/body/div[1]/div/main/div/div/div[2]/div[1]')
main_text = main_text_element.text
main_text = ' '.join(main_text.split())
# # 주어진 문구 추가
encoded = tokens_from_string(main_text, "text-davinci-003")
if len(encoded) > MAX_TOKEN - len(token_givenrequest) -completion_MAX_TOKEN:
encoded = encoded[:MAX_TOKEN - len(token_givenrequest) -completion_MAX_TOKEN]
main_text_plus = string_from_tokens(encoded,"text-davinci-003") + givenrequest
# # 4-4. 댓글 입력하기
reply_sel.send_keys(str(runCnt) + "번째 실행:" + generate_text(main_text_plus))
# # 4-5. Submit 요소 찾기
# element = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tt-btn_register')))
element = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, "tt-btn_register")))
submit_sel = driver.find_element(By.CLASS_NAME,'tt-btn_register')
# # 4-6. Submit 클릭하기
submit_sel.click()
# time.sleep(5)
show_message("완료", str(runCnt)+"번째 블로그에 댓글달기 작업이 완료되었습니다!")
# sys.exit()#멈춤!!!!!!!!!!!!!!!!!!!!!
1. AI한테 질문하는 함수
게시글의 본문과 명령을 prompt로 넘겨주고 그에 대한 답변을 리턴받는 함수입니다.
from openai import OpenAI
client = OpenAI(api_key = "my api-key")
completion_MAX_TOKEN = 256
def generate_text(prompt, model="text-davinci-003", temperature=0, max_tokens=256, top_p=1, frequency_penalty=0, presence_penalty=0):
response = client.completions.create(
model=model,
prompt=prompt,
temperature=temperature,
max_tokens=max_tokens,
top_p=top_p,
frequency_penalty=frequency_penalty,
presence_penalty=presence_penalty
)
return response.choices[0].text
# 함수를 사용하는 예제
prompt_text = "반갑습니다."
generated_text = generate_text(prompt_text)
print(generated_text)
api_key가 없으면 ai한테 질문하는 기능을 사용 할 수 없기 때문에 발급이 필요합니다.
api_key를 발급받아서 함수안에 넣어줍니다.
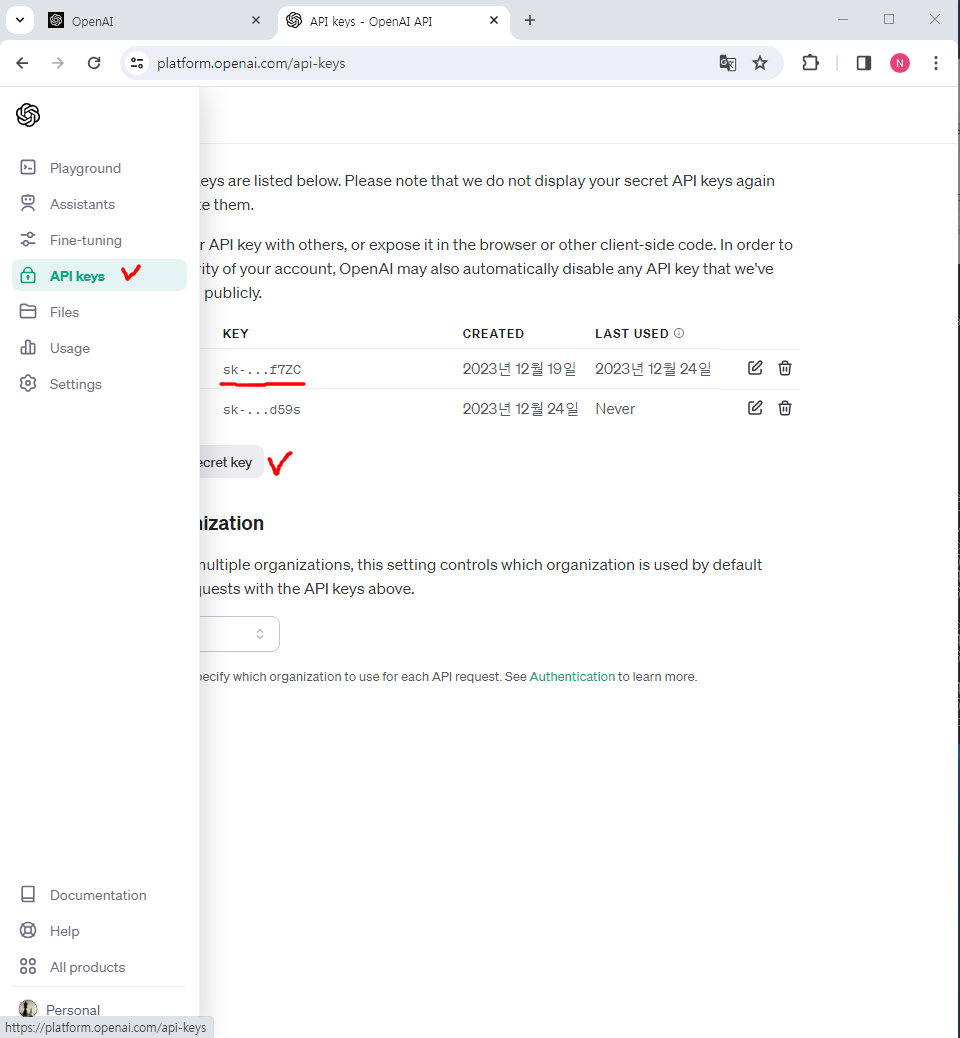
model은 text-davinci-003 사용
prompt는 질문하는 내용
temperature는 창의성
max_tokens는 ai가 대답하는 내용의 최대 크기(256토큰)
top_p는 일관성
frequency_penalty는 동일한 답변을 제한하는 정도
presence_penalty는 새로운 답변을 장려하는 정도
2. 토큰 세는 함수
ai한테 질문가능한 최대 토큰이 존재합니다.
그 토큰에 맞춰서 prompt를 만들어야 하기 때문에 토큰을 세어줄 필요가 있습니다.
토큰은 무엇인지에 대해서 짚고 넘어가겠습니다.
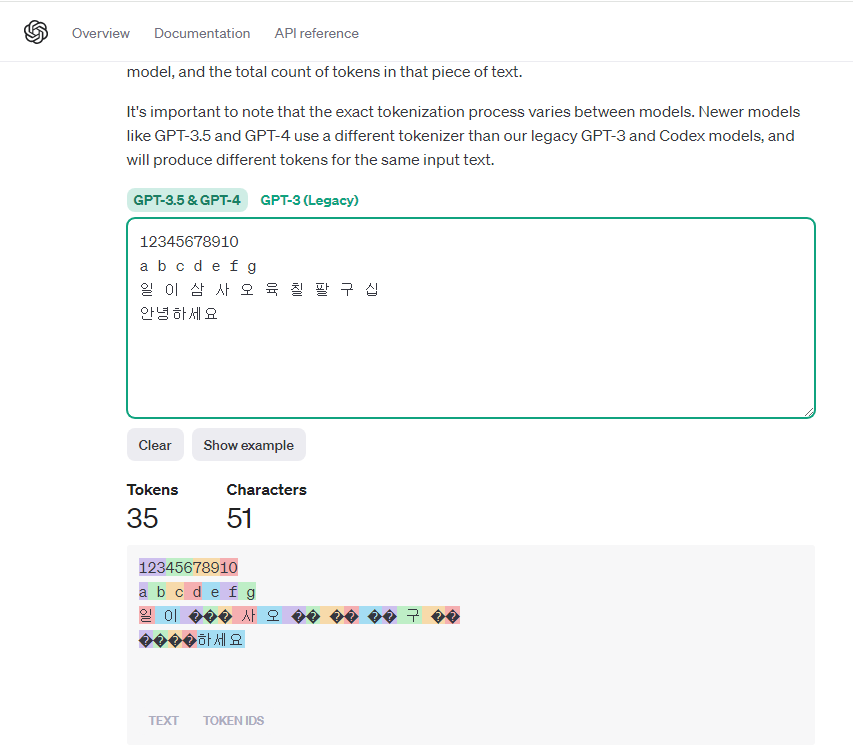
문자는 51개인데 토큰으로 계산하니 35개가 나옵니다.
토큰이란 ai모델이 문자열을 전략적으로 이해하기 위해 묶어놓은 겁니다.
모델이 상위 모델이 될수록 동일한 문자에 대해 토큰이 줄어듭니다. 더 경제적으로 토큰을 사용가능하다는 의미입니다.
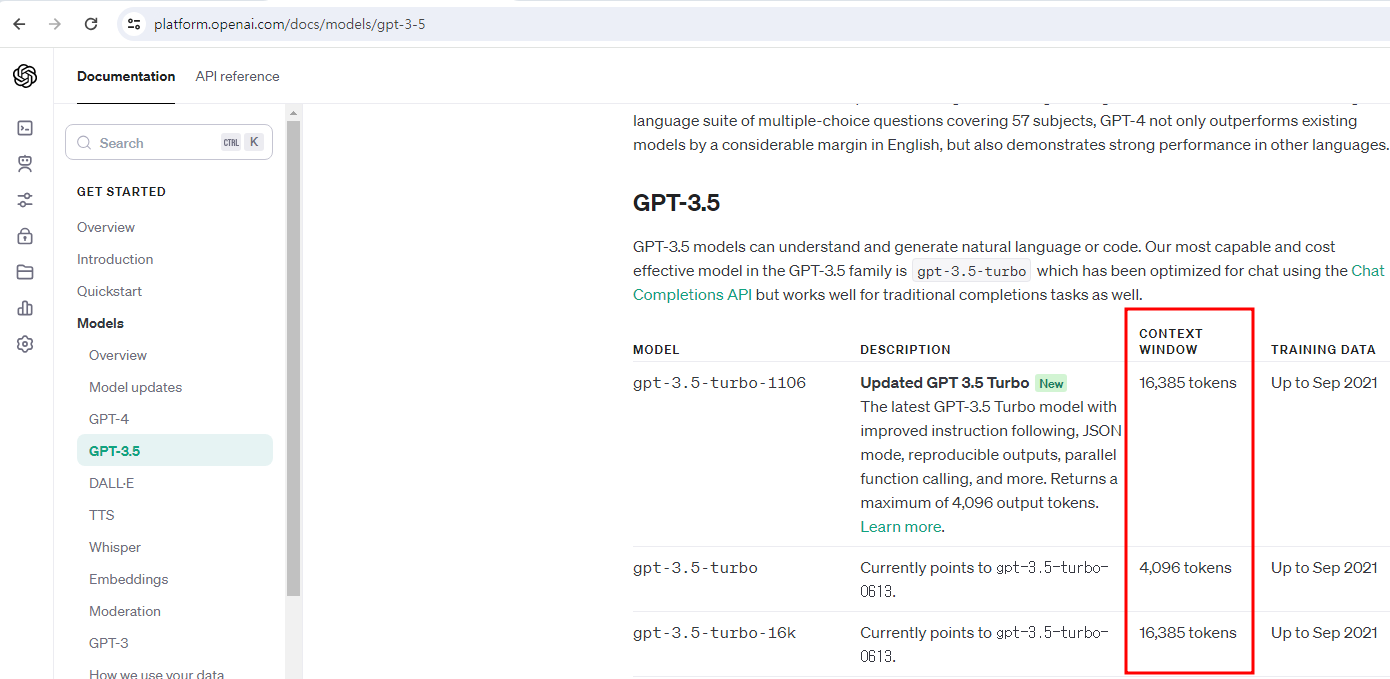
공식문서에 모델별로 사용가능한 최대 토큰수가 명시되어 있습니다.
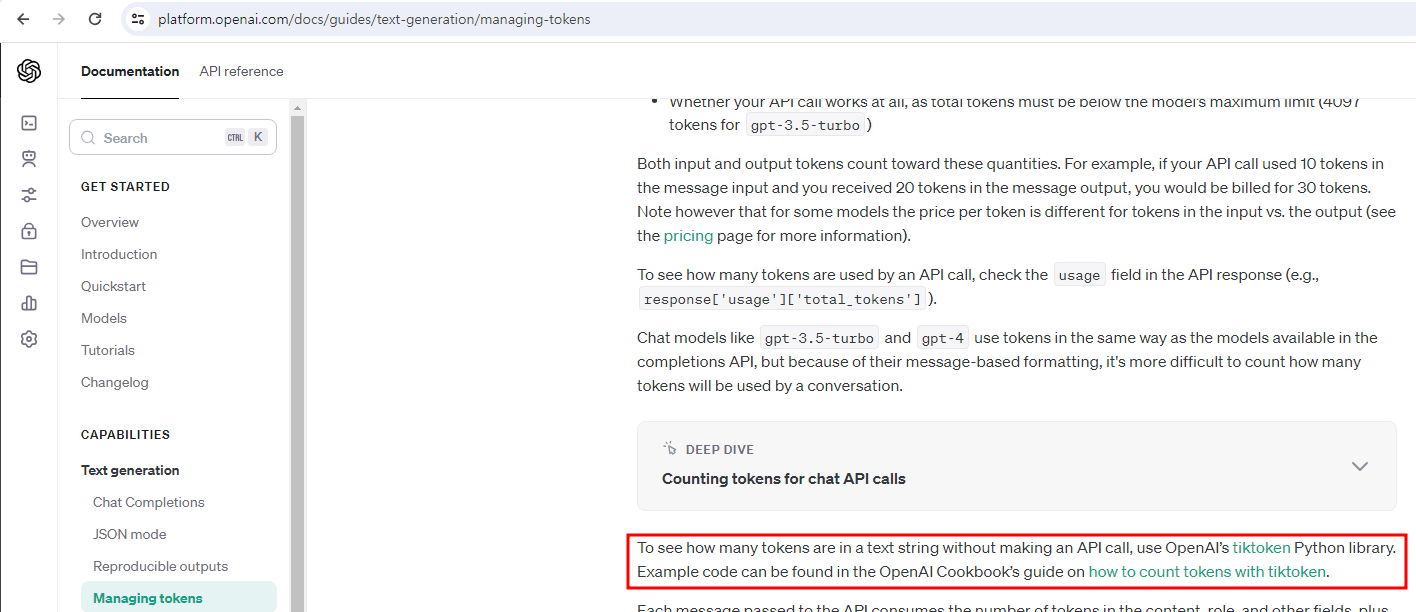
openai에서 토큰 셀 때 추천하는 파이썬 라이브러리가 존재합니다. 바로 tiktoken입니다.
이걸 사용해서 토큰 세는 함수를 만들어줬습니다.
!pip install tiktoken
import tiktoken
encoding = tiktoken.get_encoding("gpt2")
print(encoding)
print(type(encoding))
# cl100k_base gpt-4, gpt-3.5-turbo, text-embedding-ada-002
# p50k_base Codex models, text-davinci-002, text-davinci-003
# r50k_base (or gpt2) GPT-3 models like davinci
MAX_TOKEN = 4096
enc = tiktoken.encoding_for_model("text-davinci-003")
print(enc)
print(type(enc))
def tokens_from_string(string: str, encoding_name: str) -> list: #<class 'list'>
"""Returns the number of tokens in a text string."""
encoding = tiktoken.encoding_for_model(encoding_name)
encoded = encoding.encode(string)
return encoded
def string_from_tokens(tokens: list, decoding_name: str) -> str:
"""Returns the number of tokens in a text string."""
decoding = tiktoken.encoding_for_model(decoding_name)
decoded = decoding.decode(tokens)
return decoded
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.encoding_for_model(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens3. 실행 횟수 체크 함수
매번 동작 테스트 할 때 게시글마다 달리는 댓글이 몇 번째 동작인지 알기 위해 짠 코드입니다.
GPT한테

라고 질문하고 나온 답변을 그대로 긁어서 적용했습니다.
import os
def update_run_count(filename="run_count.txt"):
# 파일이 존재하지 않으면, 0으로 초기화
if not os.path.exists(filename):
with open(filename, "w") as file:
file.write("0")
# 파일에서 현재 실행 횟수 읽기
with open(filename, "r") as file:
count = int(file.read())
# 실행 횟수 업데이트 (1 증가)
count += 1
# 업데이트된 실행 횟수 저장
with open(filename, "w") as file:
file.write(str(count))
# 현재 실행 횟수 반환
return count
# 함수를 사용하여 실행 횟수를 출력
current_count = update_run_count()
print("이 프로그램은 지금까지", current_count, "번 실행되었습니다.")
4. 완료 시 알림창 띄우는 함수
이 역시

라고 하니 ai가 짜준 코드 그대로 적용했습니다.
import tkinter as tk
from tkinter import messagebox
def show_message(summary:str, context:str):
# Tkinter 윈도우 초기화
root = tk.Tk()
root.withdraw() # 메인 윈도우 숨기기
# 메인 윈도우를 최상위로 설정
root.attributes('-topmost', True)
# 메시지 박스 띄우기
messagebox.showinfo(summary,context)
# 메시지 박스가 닫힌 후 메인 윈도우 숨김 해제
root.destroy()
5. 메인 코드
1. 사이트 접속
2. 로그인
- 암호 하드코딩 주의
3. 게시글 링크 저장
4. 게시글로 이동하여 댓글달기
- 댓글칸에 내용을 입력하거나 댓글등록버튼을 누를 때 해당 요소가 준비됐는지 확인하기 위해 wait.until()함수를 사용했습니다. 코드의 속도가 웹페이지 로딩속도보다 빠를 때 종종 요소가 준비안되는 상황이 발생합니다.
메인 코드가 너무 길어 전부 설명붙이기 어렵(귀찮)습니다.
다음부턴 함수로 나누어 짜야겠다는 생각이 드네요. 질문있으시면 댓글달아주세요.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
import time
import sys#sys.exit()실행중지용
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
import tkinter as tk
from tkinter import messagebox
# 크롬 드라이버 설치 및 설정
service = Service(executable_path=ChromeDriverManager().install())
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
# 크롬 브라우저 열기
driver = webdriver.Chrome(service=service, options=options)
# 페이지의 로드 상태를 확인하는 자바스크립트
wait = WebDriverWait(driver, 10)
#화면 최대화해서 맨 앞으로 가져오기
driver.minimize_window()
driver.maximize_window()
# 원하는 사이트 접속
url = "https://weekreport.tistory.com/"
# driver.get(url)
driver.get("https://www.tistory.com/auth/login?redirectUrl=https%3A%2F%2Fweekreport.tistory.com#")
from selenium.webdriver.common.by import By
kakaologin=driver.find_element_by_xpath("/html/body/div[2]/div/div/div/div/div/a[2]")
kakaologin.click()
kakaologin_id=driver.find_element_by_xpath("/html/body/div/div/div/main/article/div/div/form/div[1]/div/input")
kakaologin_id.send_keys("abc@naver.com")
kakaologin_pw=driver.find_element_by_xpath("/html/body/div/div/div/main/article/div/div/form/div[2]/div/input")
kakaologin_pw.send_keys("myPasswd")#하드코딩 위험한 방식
kakaologin_btn=driver.find_element_by_xpath("/html/body/div/div/div/main/article/div/div/form/div[4]/button[1]")
kakaologin_btn.click()
# "link_num" 클래스를 가진 모든 요소 찾기
element = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'link_num')))
page_list = driver.find_elements(By.CLASS_NAME, 'link_num')
# 가장 마지막 요소의 href 속성 추출
last_href = page_list[-1].get_attribute('href')
# href에서 숫자(page 값) 추출
last_page_num = int(re.search(r'page=(\d+)', last_href).group(1))
# page=1부터 last_page_num까지의 URL 생성
page_urls = [f"{driver.current_url}?page={i}" for i in range(1, last_page_num+1)]
# 결과 출력 및 드라이버 종료
# URL을 저장할 리스트 초기화
givenrequest = "\n칭찬하는 말투로 댓글을 달꺼야. 기술에 대한 내용을 중점으로 30자 내외로 댓글을 출력해줘"
token_givenrequest = tokens_from_string(givenrequest,"text-davinci-003")
runCnt = update_run_count()
for page in page_urls :
article_urls = []
# 페이지의 로드 상태를 확인하는 자바스크립트
driver.get(page)
element = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'item_category')))
# 한 페이지에서 보이는 리스트
article_list = driver.find_elements(By.CLASS_NAME,'item_category')
# 각 항목의 url 담기
for article in article_list:
article_url = article.find_element(By.TAG_NAME, "a").get_attribute("href")
article_urls.append(article_url)
# 4번에서 만든 코드를 article_urls의 모든 요소에 반복 적용
for article_url in article_urls:
# 해당 URL로 이동
driver.get(article_url)
# # 4-3. 댓글 요소 찾기
element = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tt-cmt')))
reply_sel = driver.find_element(By.CLASS_NAME,'tt-cmt')
# # 본문 텍스트 추출
# /html/body/div[1]/div/main/div/div/div[2]/div[1]
main_text_element = driver.find_element_by_xpath('/html/body/div[1]/div/main/div/div/div[2]/div[1]')
main_text = main_text_element.text
main_text = ' '.join(main_text.split())
# # 주어진 문구 추가
encoded = tokens_from_string(main_text, "text-davinci-003")
if len(encoded) > MAX_TOKEN - len(token_givenrequest) -completion_MAX_TOKEN:
encoded = encoded[:MAX_TOKEN - len(token_givenrequest) -completion_MAX_TOKEN]
main_text_plus = string_from_tokens(encoded,"text-davinci-003") + givenrequest
# # 4-4. 댓글 입력하기
reply_sel.send_keys(str(runCnt) + "번째 실행:" + generate_text(main_text_plus))
# # 4-5. Submit 요소 찾기
# element = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tt-btn_register')))
element = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, "tt-btn_register")))
submit_sel = driver.find_element(By.CLASS_NAME,'tt-btn_register')
# # 4-6. Submit 클릭하기
submit_sel.click()
# time.sleep(5)
show_message("완료", str(runCnt)+"번째 블로그에 댓글달기 작업이 완료되었습니다!")
# sys.exit()#멈춤!!!!!!!!!!!!!!!!!!!!!
'AI' 카테고리의 다른 글
| AI, 쇼츠 만들어줘! 주제만 정해주면 영상까지 뽑는 AI 만들기 -1- (2) | 2024.01.06 |
|---|